C++ - 复习STL和泛型
第一讲:STL和泛型概述
认识headers、版本、重要资源
1STL
1.C++标准库具有6大部件,使用的方法,认识、使用、扩充;
2.C++SL包括C++STL六大部件和其他零碎的
3.新式的headers内的组件封装在namespace std
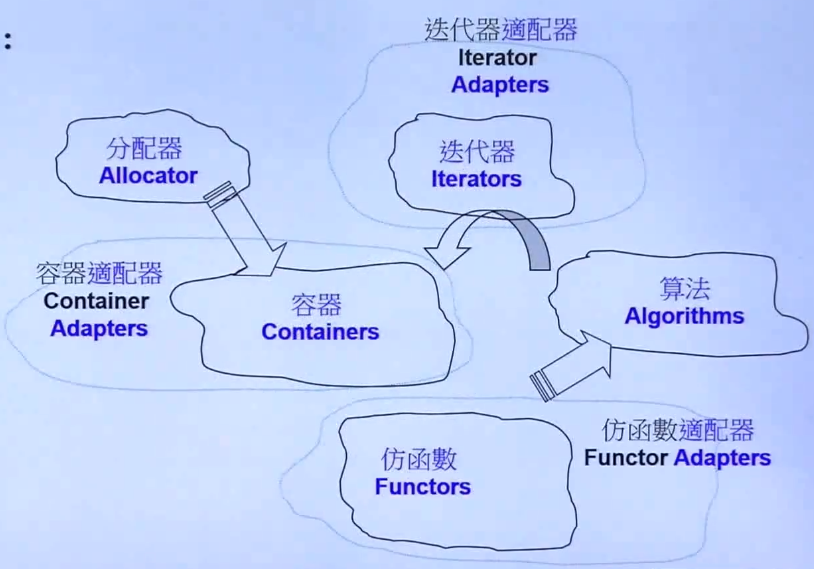
STL体系架构
六个部件
- 容器containers、分配器allocators、算法algorithms、迭代器iterators、适配器adapters、仿函数Functors
1 | //获取大于等于40的数 |
not1(bind2nd(less
- 复杂度Big-oh 其中n为一个比较大的规模
“前闭后开”区间用于标准库容器;
3.1 迭代器定义一contianer<T>::iterator ite =c.begin()
3.2 for(decl:coll){statement}
3.3 for(auto& elem:vec){elem*=3};
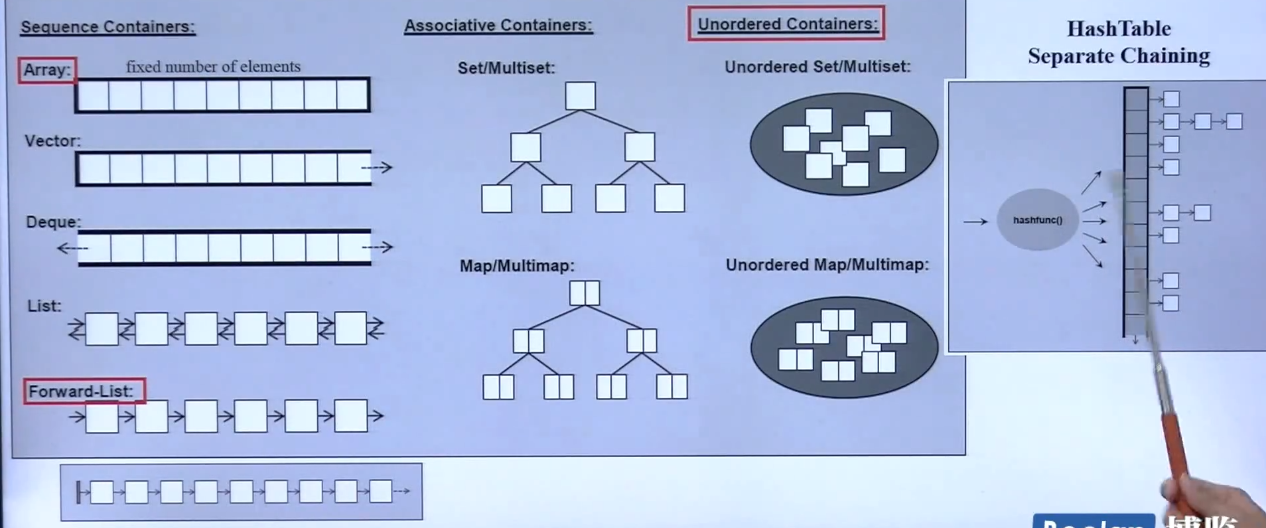
容器之分类与各种测试
容器分类
sequence contaniners:array、vector 、deque、list、forward_list
associative contanniers:set/multiset、map/multimap(STL没有规定怎么实现,一般编译器采用红黑树实现)
unordered contaniners不定序:unordered_(hash table实现,其用separate chaining创建)
- 呼叫时间调用clock()
- 全局函数前面加上::,比如
::find - 容器自身算法有的时候,用容器自身的
容器扩充
vector的扩展是两倍扩展,新空间并拷贝原值
forward_list,一个个扩充
deque,左右边界满,扩充
分配器
一个类,不建议单独使用,应该用容器本身或者new和delete
1 | int *p; |
源代码之分布(VC,GCC)
2.91源代码的说明
泛型GP和OOP
OOP(objective-Oriented programming)企图将date和methods合在一起;
GP(generic programming)将date和methods分开来
- list不能用sort(),因为不能随机访问,也就不能用二分查找
所有algorithms,其内最终设计元素本身的操作,无非就是比大小;所以类型本身类需要重载比大小操作符
基础回顾
- 函数模板
template <typename T> - 类模板
template <class T> - 成员模板
类模板中泛化、特化、偏特化
泛化:操作符重载和模板的复习
Specialization 特化(全特化)
在泛化的模板基础上,指定类型
也就是 class allocator<void> 指定了 _Tp为void类型

Partial Specialization 偏特化
分为
- 数量上(多参数中某些特化)
1 | //先声明类模板 |
- 范围上(随意类型到指针 特化为 指针类型 或者const类型)

第二讲:STL容器解析
分配器allocator
学习目的:理解效率,不要单独用
operator new()实际上使用malloc()
malloc()的理解
底层都是malloc()和free()使用分配内存;
malloc()分配时有额外的开销;
allocators()的两个成员函数
VC6+中的allocate和deallocate,只是::operator new和::operator delete完成的;
GC和BC都也是malloc,额外开销有点大;
容器
容器之间的关系

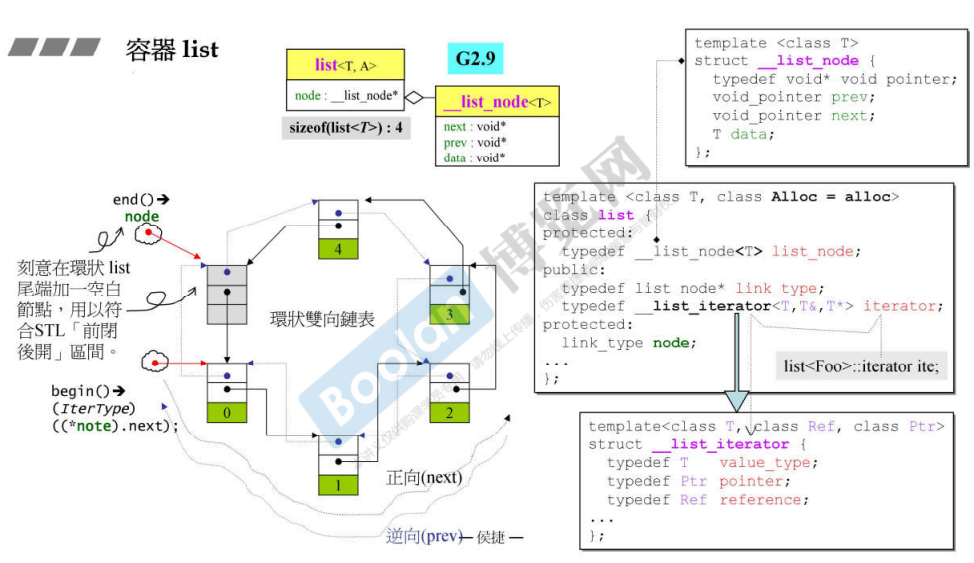
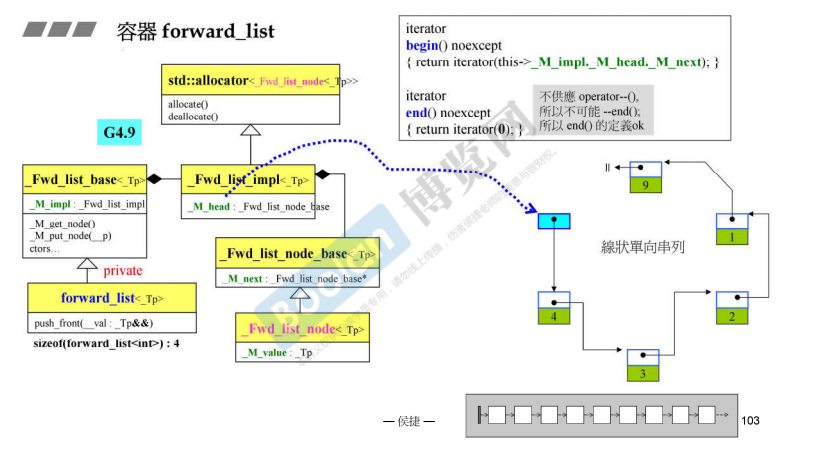
list
实际上里面只有一个指针(G2.9),G4.9里存了两个指针
void* 无类型指针:void指针可以指向任意类型的数据,亦即可用任意数据类型的指针对void指针赋值。
简要包括
- 一堆typedef
- 每个节点的设计
- 一些操作符重载
操作符重载的++符
前++重载函数无入参;后++一个入参。
1 | self& operator++(){node=(link_type)((*node).next); return *this;}//前++ |
C++不允许后++两次;
操作符重载*

G4.9对G2.9的改进

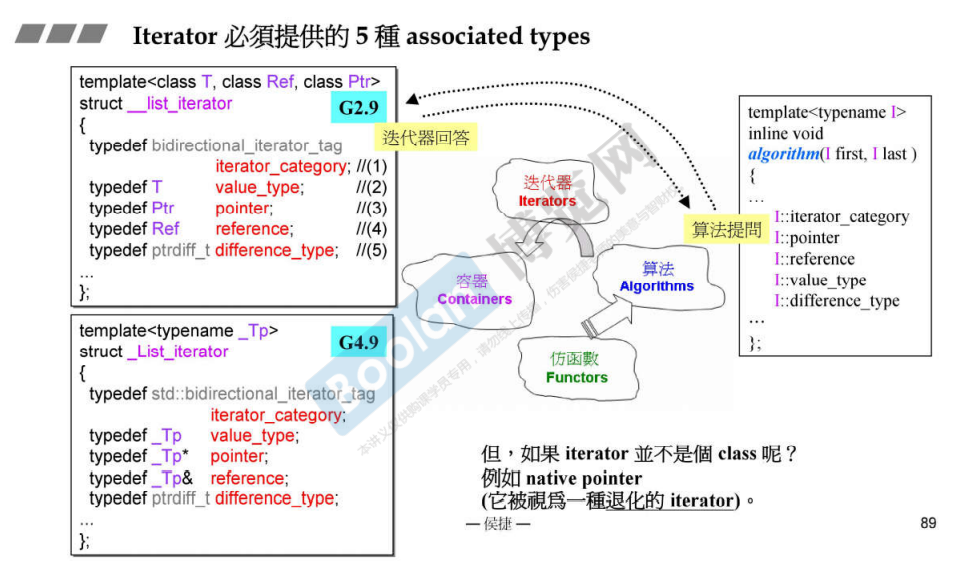
Iterator需要遵循的原则
iterator的五种associated type需要定义出来,以便回答算法调用时的提问;
value_type 元素类型
difference_type 距离类型
iterator_category 迭代器类型:
1、input_iterator:istream独有的迭代器。
2、output_iterator:ostream独有的迭代器。
3、forward_iterator:继承自input_iterator,单向走的迭代器,只能走一个,不能跳。如forward_list、单向list的hashtable
4、bidirectional_iterator:继承自forward_iterator,双向走的迭代器,只能走一个,不能跳。如list、rb-tree、双向list的hashtable
5、random_access_iterator:继承自bidirectional_iterator,可以跳的迭代器。如array、vector、deque。
reference
pointer
后两种从来没用到
萃取traits特性
如果iterator不是一个类,而是指针,不能用typedef咋办????
方法是增加中间层——萃取机iterator_traits

第一种是问I,第二种用偏特化区别指针和常量指针
vector
实际上是三个指针,大小为12

容量扩充函数的实现
当容量不够了,找新空间并两倍成长(有的时候是1.5 看版本),拷贝前部,拷贝后部


traits特性
G2.9也是依靠萃取机作为中介,区分指针和迭代器类;G4.9也是,只是typedef很多次,评价为乱七八糟
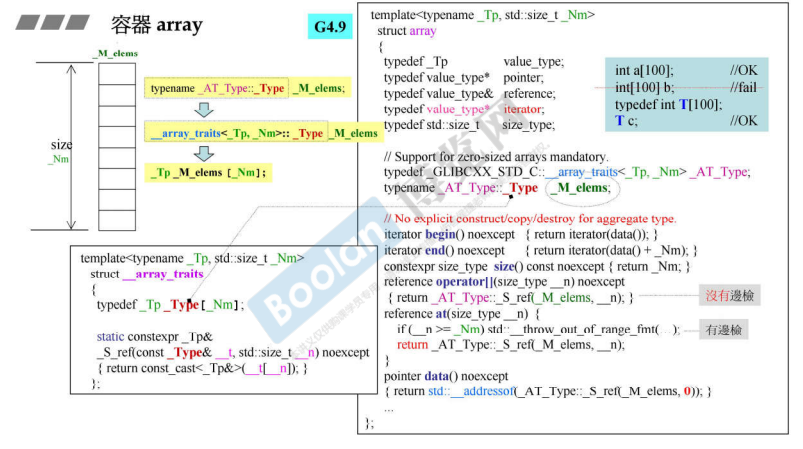
array
没有构造、析构函数
array<int ,10> myArray;

forward_list
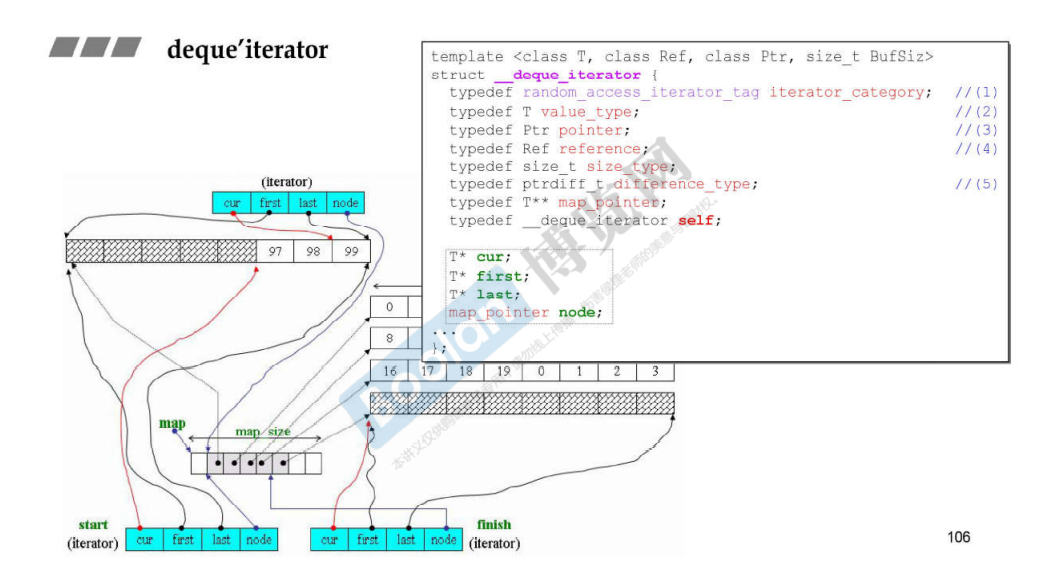
deque
分段连续;
扩充时分配新的缓冲区,并且指针指向;
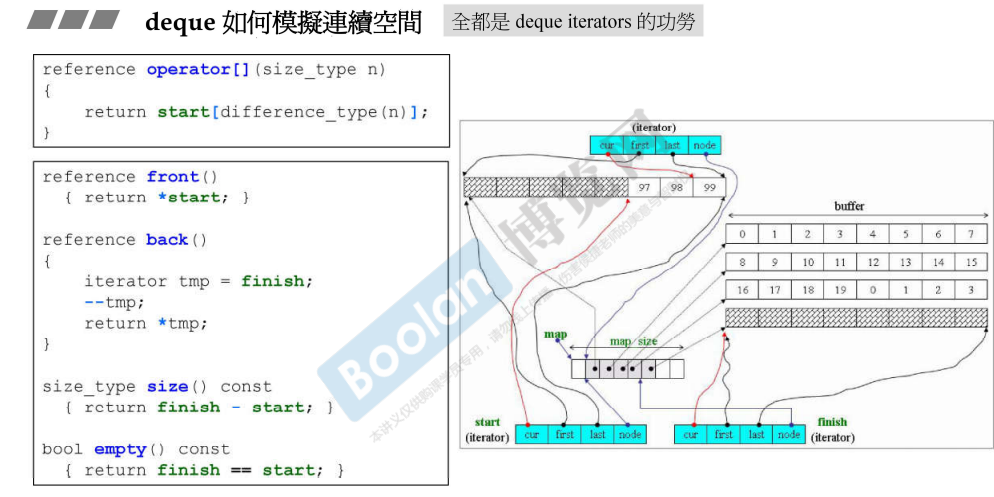
iterator有四个元素,node指向控制中心;当cur到达last后,需要通过node指向下一个buffer;
控制中心是vector,当缓冲区数量不够的时候,两倍增长;
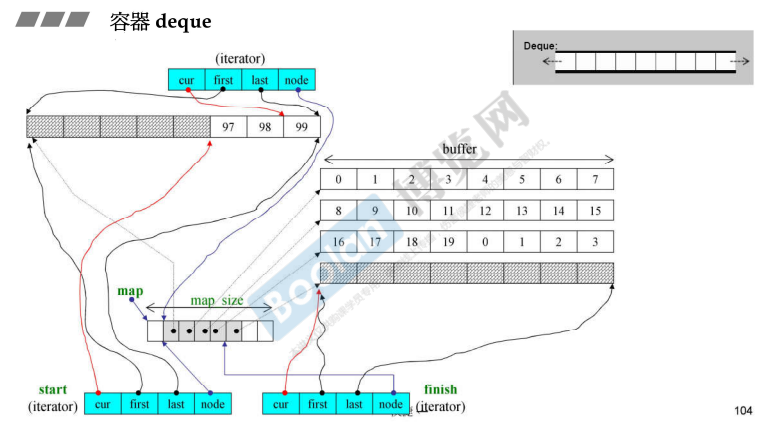
简要包括
start和finish(iterator),一个map(T**) ,一个map_type(size_type);其中iterator有四个元素,大小是16;
总大小是16+16+4+4=40;

insert
判断指定位置靠近头还是尾=》推动原来的元素往前或往后=》在指定位置插入新元素
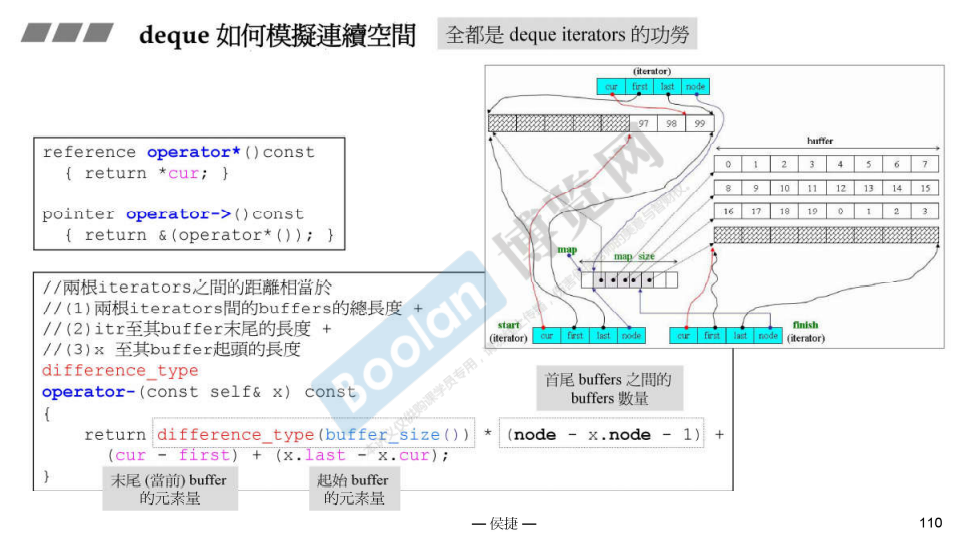
deque如何模拟连续空间
全部都是iterator的功劳
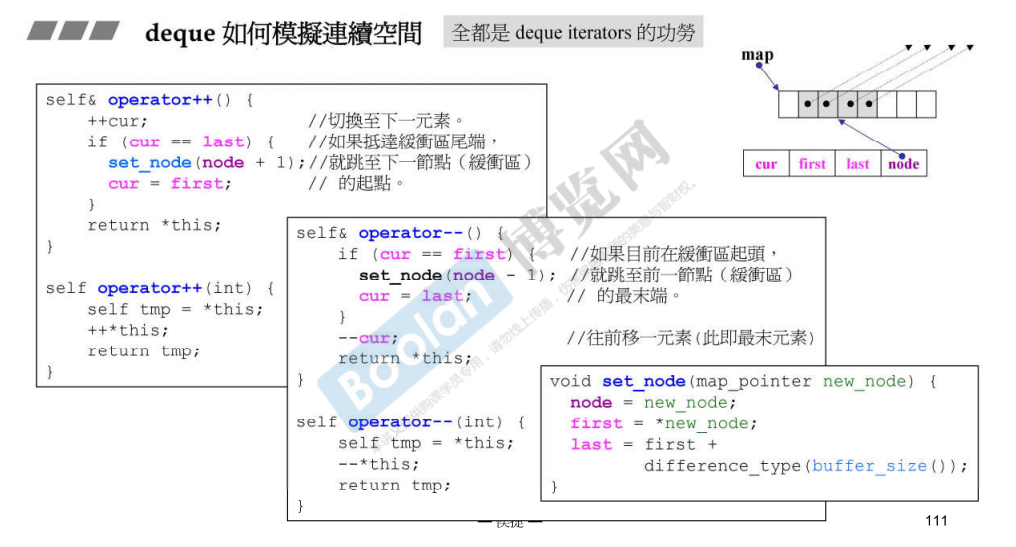
++调用set_node;–先判断cur
后++调用前++
+调用+=;+=的时候,判断有没有超出当前缓冲区,并调整缓冲区位置
-调用-=;-=调用+={return *this += -n;}

G4.9对G2.9的改进
- deque类继承;
- 入参去掉了buffer_size,只有两个了
queue和stack
这两个是容器适配器;


一些特性:
- 不允许遍历,不提供iterator;
- 包含deque,并且封锁一些接口;这两者实际上list也可以作为底层容器,但是慢;stack也可以用vector作为底层容器,queue不能,因为没有pop()操作;都不能用set和map作为底层;
RB-Tree
红黑树特性
红黑树是平衡二叉搜索树中常被使用的一种;排序规则有利search和insert,并保持高度平衡;
红黑树提供遍历和iterators;按照正常规则遍历,就能得到排序状态;
不应使用iterators改变元素值,但是编程里面有没有禁止此。如此设计,是因为rb_tree即将为set和map服务,map允许元素的date被改变,只有元素的key才是不可改变的;
红黑树提供两种insertion操作:inset_unique()和insert_equal()
容器re_tree
value分为key和date两部分
模板参数5个
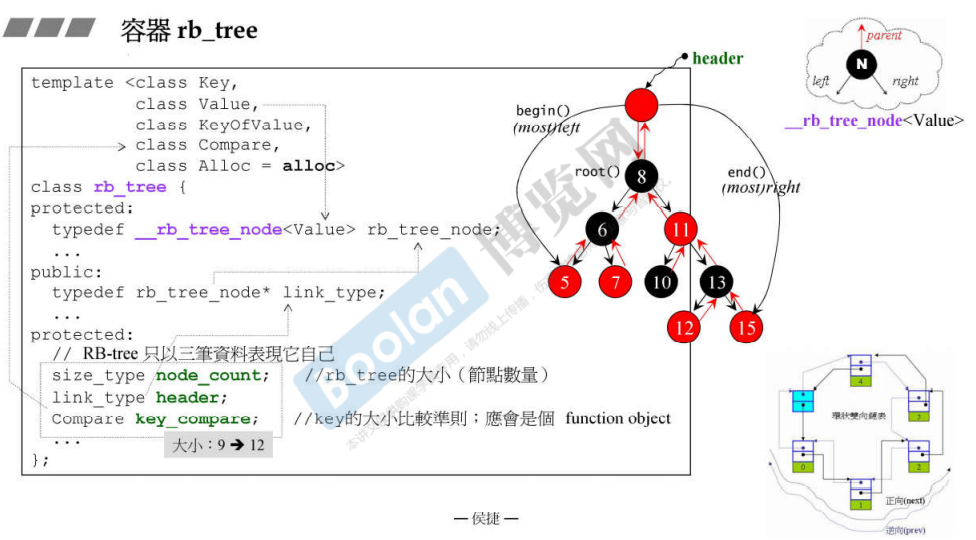
使用举例
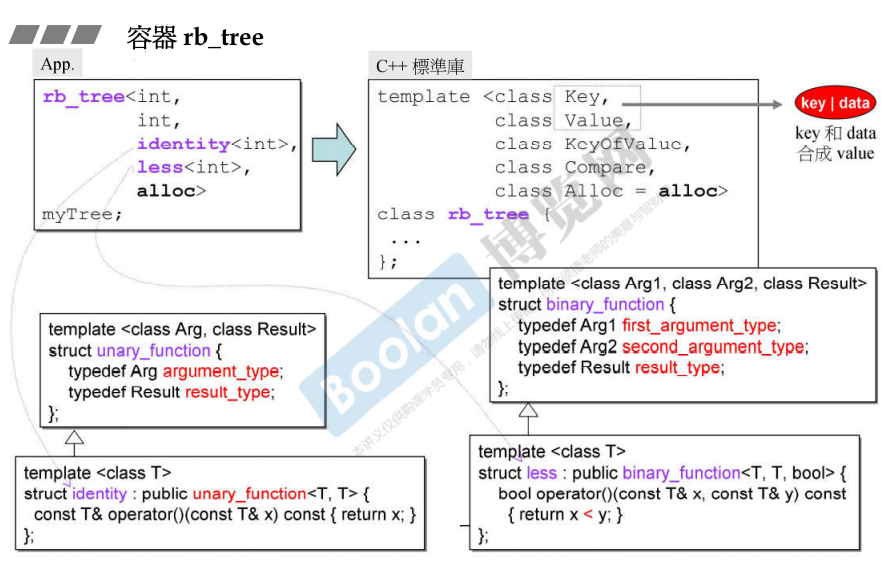
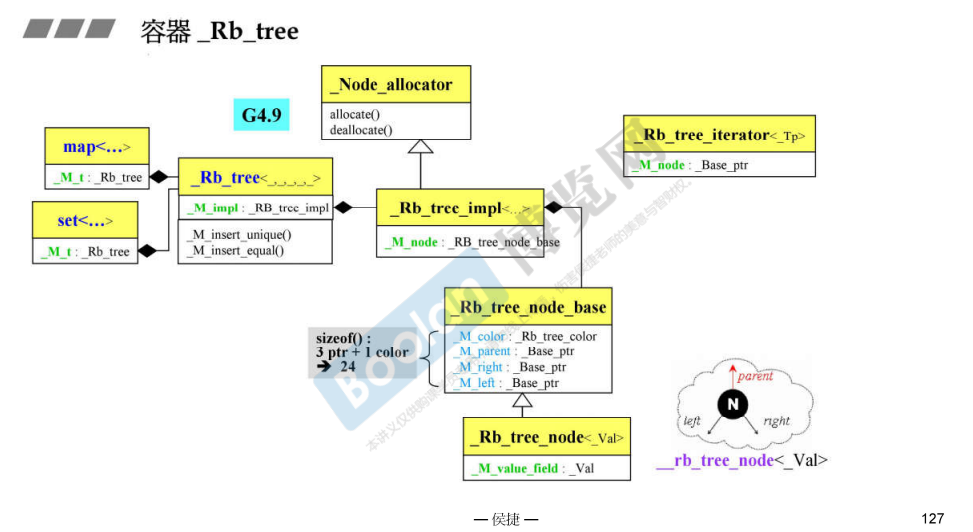
G4.9对G2.9的修改
改为容器_Rb_tree
新版是24个字节
set/multiset
内含红黑树,set也是一个container adapter容器适配器
set的key就是value;
set的迭代器是const_iterator,不能修改
inset_unique()和insert_equal()的区别

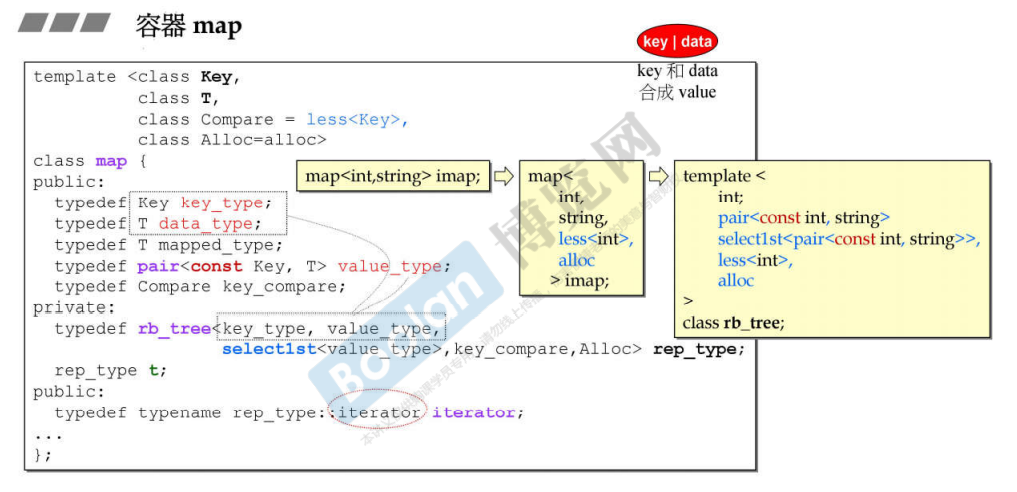
map/multimap
以rb_tree为底层结构,自动排序
无法用iterators改变元素的key,但是可以改变date;底层实现的iterator就是红黑树的,不做任何约束,但是在模板参数设置时pair<const Key,T> value_type
multimap不能用[]插入
lower_bound二分查找,在有序数列中查找与value相同第一元素的迭代器,如果没有则返回第一个>=value的元素的迭代器,再没有就返回end();也就是说不破坏排序得以安插value的第一个适当的位置;
既然[]判断元素不存在的时候,也是调用insert,直接调用insert比较快

hashtable
散列表比红黑树简单
如果发送碰撞,用链表串Separate Chaining在一起;但是链表太长(元素个数比桶个数多),要把它打散,就是把桶扩大一倍,并取最近的素数(实际上备选的list中元素已经预选好)作为新的桶个数,所有元素重新计算一遍;

模板参数6个:Value, Key, HasFcn, ExtractKey, EqualKey, Alloc
Data大小19(20):hash(1), equals(1), get_key(1), buckets(12),num_elements(4)

HashFunction的设置

unordered容器

第三讲:STL算法
算法是模板函数,其他都是模板类;
算法看不到容器,所有信息都由迭代器告知
两种形式,包含Cmp和不包含:
1 | template<typename Iterator,typename Cmp> |
迭代器
Random Access和不能;双向和单向
迭代器的分类继承图
这样的好处是,用萃取提取迭代器的类型是,可以用不同入参的类型重载提取函数


在头文件typeinfo中函数typeid(),能得到编译后的类型名称

istream_iterator和ostrean_iteraror
这两种的iterator_category


逆向迭代器reverse_iterator
调用迭代器适配器

iterator对算法的影响
distance算法
:返回值,输入参数
- 其中randomaccess类型只需要相减,但是input类型只能一步步操作,差异非常大
- distance()调用子函数_distance()的不同重载,这是常见的处理方法

advance()算法
与distance不同,这里用iterator_category()函数返回迭代器的类型

copy()算法

destroy()算法

unique_copy()算法

小结对算法的影响
继承可以翻译为is a
算法源码对迭代器类型的暗示是通过形参的名字告诉你,但是必须接受所有类型的迭代器;

算法例子剖析
按照算法的标准样式,区别STL的算法和普通函数
算法例子11个
accumulate()算法
第三个参数可以是自定义函数或者仿函数的对象

for_each()算法

replace()算法

count()算法
迭代器类型非random_access的不能用
关联容器用自带的快多了

find()算法
迭代器类型非random_access的不能用
关联容器用自带的快多了

sort()算法
关联容器自带排序的

binary_search()算法
调用lower_bound()二分搜寻
归纳后:
lower_bound( begin,end,num):从数组的begin位置到end-1位置二分查找第一个大于或等于num的数字,找到返回该数字的地址,不存在则返回end。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。
upper_bound( begin,end,num):从数组的begin位置到end-1位置二分查找第一个大于num的数字,找到返回该数字的地址,不存在则返回end。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。

仿函数functors
函数对象,类中重载小括号,STL定义很多仿函数

仿函数可适配的条件
:需要继承一元和二元仿函数的基类,也就是unary_function或者binary_function其中一个。继承之后,才可回答被仿函数适配器的提问,实参的类型是什么。

适配器Adapters
改造器,要改造原有的部件的功能,用内含而不是继承的方式包含原有的部件
存在多种适配器:Contanier Adapters, Functor Adapters, Iterator Adapters

容器适配器
stack,queue内含的deque并且改造函数接口

函数适配器
修饰function形成function的样子
bind2nd()函数和binder2nd函数对象
less
()和40被记在binder2nd类的Data中,等之后类内operatpr()调用后再拿出来用; bind2nd()函数返回临时对象binder2nd;
适配器操作后,需要询问算法的入参(1或2个参数的类型)和结果(返回值的类型)

新型适配器 ,bind来取代原有的

not1()
一元谓词;
记录入参,返回!pred,C17已经弃用
bind()和占位符
新版STL中取代之前的函数对象和函数
- 对于函数,绑定对象,设置占位符以备之后调用函数时作为入参;占位符
_1和_2的就是参数的顺序 - 还可以改变模板参数,绑定返回类型比如
bind<int> (my_divide,10,2); - 还可以把成员函数,绑定给要做用的对象,比如
auto f1=bind(&MyPair::multiply,_1);f1(ten_two);

std::bind可以绑定:
- functions;
- function objects;//这种是注释讲了,也就是把方程改为仿函数
- member functions,_1必须是个object地址;//比如说
auto f1 = bind(&MyPair::multiply,ten_two); - date member,_1必须是某个object地址;//比如说
auto f1 = bind(&MyPair::b,_1);,调用f1(ten_two)只会输出成员b的数,这个很特别
迭代器适配器
reverse_iterator

inserter
不同于赋值assign,重载操作符,使得=变为insert操作

X适配器
ostream_iterator
输出迭代器的适配器,直接用于输出;
实现方式也是用重载算法的操作符operator=为<<
1 | vector<int> myvector{1,2,3,4}; |

istream_iterator
输出迭代器的适配器
实现是重载算法的operator=为>>
没有参数的作为标兵,有参数的绑定输如cin,读当前it指向的值,++往下读;

下面这个连算法的first和last迭代器都改为了iit和eos,但是算法流程框架没变,第三个参数insert(c,c.begin())重载了=为insert操作;
- 当创建了istream_iterator后,这个类自动实现++也就是立刻read,往下进行。

第四讲 STL其余体系结构
一个万用的hash fuction
- 其中…是省略一些参数的写法, variadic templates可变化的模板,可以放任意的参数
- 每一个分出来seed,计算出,最后当做hashcode,一直到全部拆解完成加上hashcode
- hash_combine()中seed的计算用的是黄金分割

用例尝试,作为unordered_set的hashfunction(第二参数)


tuple,用例
一些数据的组合,相对于pair

- 创建用括号初始化,也可以用make_tuple创建
- 取出成员用get<1>(t1)
- 整个tuple可以用于比较,相同成分的tuple比较,不同成分tuple的比较
- 整个tuple可以互相赋值,整个tuple可以cout
- 可以初始刷为具体的值,然后用tie绑定变量到值
- tuple_size
::value可以得到tuple的成员数;tuple_element<1,t1>::type f1=10可以获得指定元素的类型;
tuple实现
还是用到variadic templates;tuple类继承他自己,递归继承他的尾部,头部作为成员数据,用于声明变量;当为空就结束

type traits原编程
C++ 提供元编程设施,诸如类型特性、编译时有理数算术,以及编译时整数序列。
利用特化偏特化,判断构造函数、拷贝构造、析构函数等重不重要

C++11中定义了很多的元编程,用于各种类型的查询


用traits分析string
实际上使用string,是调用basic_string<char>

traits实现
基本都是泛化和偏特化实现的
remove_const和remove_volatile,用特化来拿掉
_is_void用特化返回void类型,实现

is_integral

调用编译过程的接口,找不到源代码,grep的工具可以查看


cout
cout的类型为_IO_ostream_withassign,继承自ostream,其中重载了和对不同入参的<<操作、


moveable元素(移动构造)
对于vector速度效能的影响
加入move功能的容器,速度上效率会高
其中MCtor是有move功能的构造函数。CCtor是没有move功能的构造函数。
其中std::move()是有move的拷贝构造。
对list的影响
list是逐个创建,时间效率差距不大;deque其实也影响不大;
但是除了创建,其他操作可能也有影响
一个moveable类
是一种浅拷贝,并且在析构中判断是否要delete指针