分布式 - GFS论文阅读
GFS
CAP理论
①Consistency 一致性:所以节点访问同一份最新的数据副本。
②Availability 可用性:所有读写请求在一定时间内得到非错响应,不会一直等待(但不能保证数据是最新的数据)。
③Partition tolerance 分区容忍性:在网络分区的情况下,被分隔的节点仍然能够正常对外服务
对于一个分布式系统来说,三者只能取其二。
考虑对于分布式环境,P一定是存在的,没有网络分区和网络波动情况下,正常CAP,当出现网络分区的时候,那么一致性和可用性就要抛弃一个。
PA:存在网络分区,那么网络中的节点之间就有可能数据不一致;比如往节点A中写入数据,B节点由于网络原因没有同步数据过去,如果此时往B节点读取数据是不能读到数据的,所以在存在网络分区的情况下,这个时候如果系统可用,那么数据是不可能保持一致的。
PC:两个节点网络隔离了,想要保证数据一致性只能等待网络恢复,将数据同步,才能读取到数据;也就是说如果想要保证数据强一致性,那么在等待网络恢复的过程中,是不能对外提供服务的,这个时候系统就不可用。
高容错的实现难点:
- 高性能的要求 导致需要 跨机器对数据分片
- 大量计算机 导致必然 会有很多崩溃
- 容错解决奔溃情况 采用的机制是 副本;副本需要实施更新,保持副本一致;一致性高 必然导致 性能开销。
一致性实现的难点 :
- 并发性,保证线程安全,可以通过之后的分布式锁等机制解决
- 故障和失败案例 :为了容错会用复制,但是不成熟的复制会导致读者在不做修改的情况下读到两次不同数据。
GFS简介
GFS旨在保持高性能,且有复制、容错机制,但很难保持一致性,现在谷歌已经不用了; 在论文中可以看到mapper从GFS系统(上千个磁盘)能够以超过10000MB/s的速度读取数据。论文发表时,当时单个磁盘的读取速度大概是30MB/s,一般在几十MB/s左右。
GFS的几个主要特征:
- Big:large data set,巨大的数据集
- Fast:automatic sharding,自动分片到多个磁盘
- Gloal:all apps see same files,所有应用程序从GFS读取数据时看到相同的文件(一致性)
- Fault tolerance:automic,尽可能自动地采取一些容错恢复操作
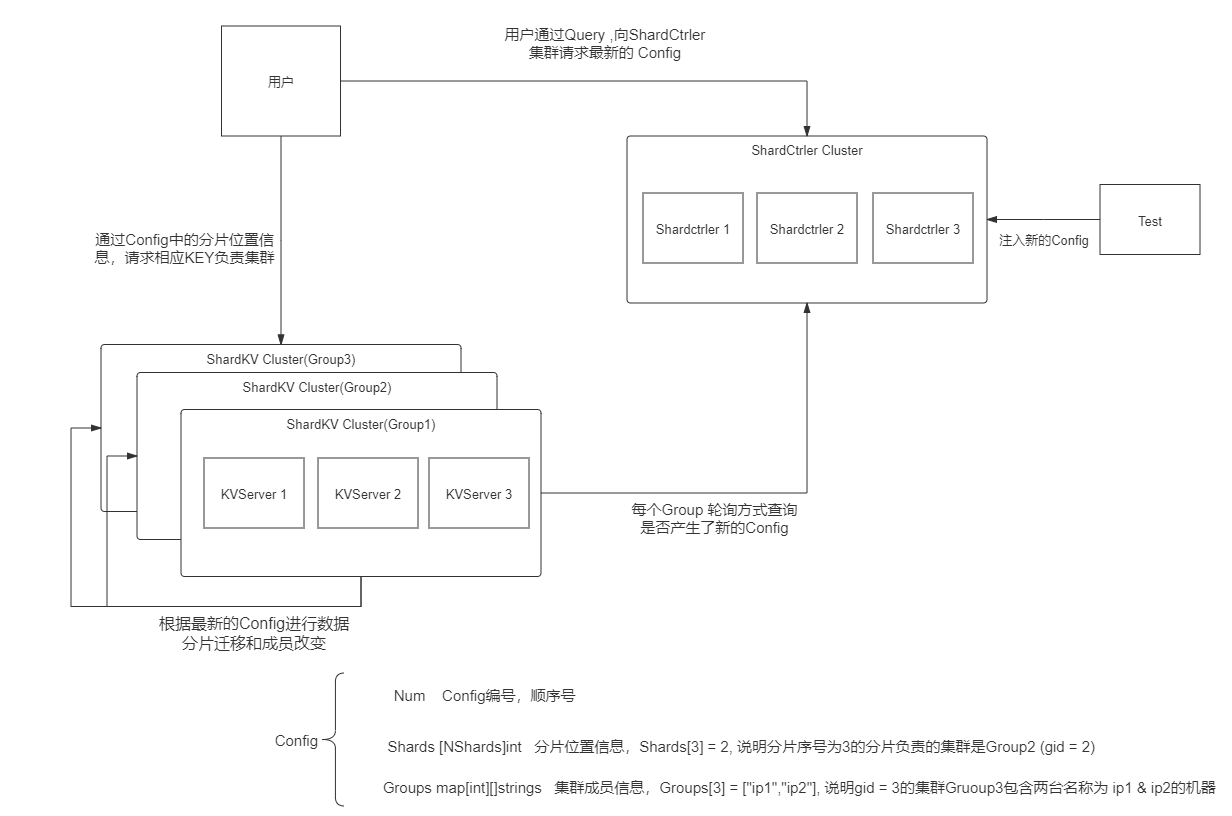
GFS主要包含三种节点:
• GFS client:维持专用接口,与应用交互。
• GFS master:维持元数据,统一管理chunk位置与租约。
• GFS chunkserver:存储数据
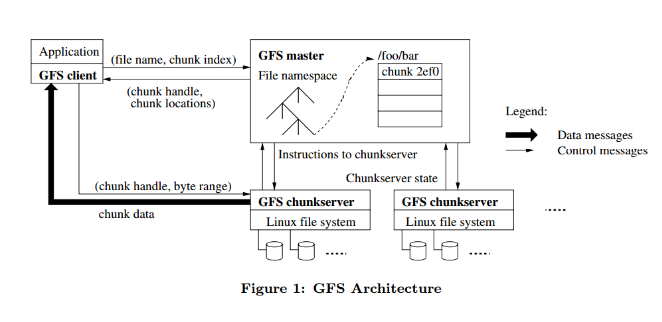
GFS存储设计
考虑到文件可能非常大,并且大小不均。GFS没有选择直接以文件为单位进行存储,而是把文件分为一个个chunk来存储。GFS把每个chunk设为64MB, 这个单位是比较大的
chunk在chunkserver中的分布:

GFS的Master的工作
维护文件名到块句柄数组的映射(file name => chunk handles) filename -> chunk handles -> chunk server \ version
这些信息大多数存放在内存中,所以Master可以快速响应客户端Client
维护每个块句柄(chunk handle)的版本(version)
维护块存储服务器列表(list of chunk servers)
- 主服务器(primary)
- Master还需维护每一个主服务器(primary)的租赁时间(lease time)
- 次要服务器(secondaries)
- 典型配置,即将chunk存储到3台服务器上
- 主服务器(primary)
log+check point:通过日志和检查点机制维护文件系统。所有变更操作会先在log中记录,后续才响应Client。这样即使Master崩溃/故障,重启时也能通过log恢复状态。master会定期创建自己状态的检查点,落到持久性存储上,重启/恢复状态时只需重放log中最后一个check point检查点之后的所有操作,所以恢复也很快。
这里需要思考的是,哪些数据需要放到稳定的存储中(比如磁盘)?
比如file name => chunk hanles的映射,平时已经在内存中存储了,还有必要存在稳定的存储中吗?
需要,否则崩溃后恢复时,内存数据丢失,master无法索引某个具体的文件,相当于丢失了文件。
chunk handle 到 存放chunk的服务器列表,这一层映射关系,master需要稳定存储吗?
不需要,master重启时会要求其他存储chunk数据的服务器说明自己维护的chunk handles数据。这里master只需要内存中维护即可。同样的,主服务器(primary)、次要服务器(secondaries)、主服务器(primary)的租赁时间(lease time)也都只需要在内存中即可。
chunk handle的version版本号信息呢,master需要稳定存储吗?
需要。否则master崩溃重启时,master无法区分哪些chunk server存储的chunk最新的。比如可能有服务器存储的chunk version是14,由于网络问题,该服务器还没有拿到最新version 15的数据,master必须能够区分哪些server有最新version的chunk。
GFS数据读取流程
GFS通过Master管理文件系统的元数据等信息,其他Client只能往GFS写入或读取数据。
应用并发的通过GFS Client读取数据时,单个读取的大致流程如下:
- Client向Master发起读数据请求
- Master查询需要读取的数据对应的目录等信息,汇总文件块访问句柄、这些文件块所在的服务器节点信息给Client(大文件通常被拆分成多个块Chunk存放到不同服务器上,单个Chunk很大, 这里是64MB)
- Client得知需要读取的Chunk的信息后,直接和拥有这些Chunk的服务器网络通信传输Chunks
GFS文件读取
- Client向Master发请求,要求读取X文件的Y偏移量的数据
- Master回复Client,X文件Y偏移量相关的块句柄、块服务器列表、版本号(chunk handle, list of chunk servers, version)
- Client 缓存cache块服务器列表(list of chunk servers)
理解: 只有一个Master,所以需要尽量减少Client和Server之间的通信次数,缓冲减少交互 - Client从最近的服务器请求chunk数据(reads from closest servers)
理解: 因为这样在宛如拓扑结构的网络中可以最大限度地减少网络流量(mininize network traffic),提高整体系统的吞吐量 - 被Client访问的chunk server检查version,version正确则返回数据
理解: 为了尽量避免客户端读到过时数据的情况。
GFS文件写入
主要是关注文件写入的append操作,在mapreduce 中,reduce处理后计算结果需要append到file中
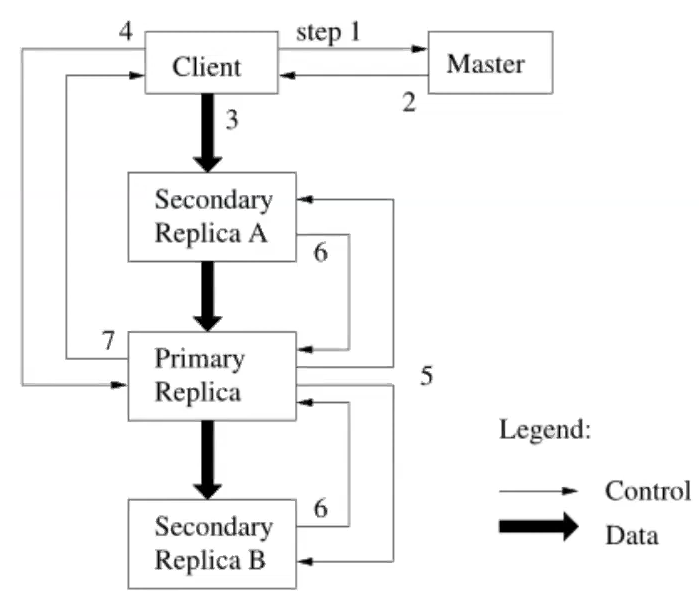
Client向Master发出请求,查询应该往哪里写入filename对应的文件。
Master查询filename到chunk handle映射关系的表,找到需要修改的chunk handle后,再查询chunk handle到chunk server数组映射关系的表,以list of chunk servers(主副本primary、secondaries、version信息)也就是得到所有该文件的chunkserver并且附加上版本号作为Client请求的响应结果
接下去有两种情况,已有primary和没有primary(假设这是系统刚启动后不久,还没有primary)
有primary,(primary:主文件副本,也就是正常情况下对外读写的文件;secondaries: 其他副本)
继续后续流程
无primary
master在chunk servers中选出一个作为primary,其余的chunk server作为secondaries
(暂时不考虑选出的细节和步骤)
- master会增加version(每次有新的primary时,都需要考虑时进入了一个new epoch,所以需要维护新的version),然后向primary和secondaries发送新的version,并且会发给primary有效期限的租约lease。这里primary和secondaries需要将version存储到磁盘,否则重启后内存数据丢失,无法让master信服自己拥有最新version的数据(同理Master也是将version存储在磁盘中)。
Client发送数据到想写入的chunk servers(primary和secondaries),有趣的是,这里Client只需访问最近的secondary,而这个被访问的secondary会将数据也转发到列表中的下一个chunk server,此时数据还不会真正被chunk severs存储。(即上图中间黑色粗箭头,secondary收到数据后,马上将数据推送到其他本次需要写的chunk server)
理解: 这么做提高了Client的吞吐量,避免Client本身需要消耗大量网络接口资源往primary和多个secondaries都发送数据。数据传递完毕后,Client向primary发送一个message,表明本次为append操作。
primary此时需要做几件事:
- primary此时会检查version,如果version不匹配,那么Client的操作会被拒绝
- primary检查lease是否还有效,如果自己的lease无效了,则不再接受任何mutation operations(因为租约无效时,外部可能已经存在一个新的primary了)
- 如果version、lease都有效,那么primary会选择一个offset用于写入
- primary将前面接收到的数据写入稳定存储中
primary发送消息到secondaries,表示需要将之前接收的数据写入指定的offset(更新其他副本)
secondaries写入数据到primary指定的offset中,并回应primary已完成数据写入
primary回应Client,你想append追加的数据已完成写入
GFS一致性
appen一次之后,read返回什么结果
例如: M(maseter),P(primary),S(Secondary)
某时刻Mping不到P了,那咋办?
假设选出新P,那可能旧P还在和CLient交互,两个P同时存在叫做脑裂,会出现严重问题,比如数据写入顺序混乱等问题,严重的脑裂问题可能会导致系统最后出现两个Master。
所以依照M知道的旧P的lease,在旧Please期限结束之前,不会选出新P,也就是M和P无法通信,但是P还可能和其他Client通信
强一致性的保证
保证 所有S都成功写入或者都不写入
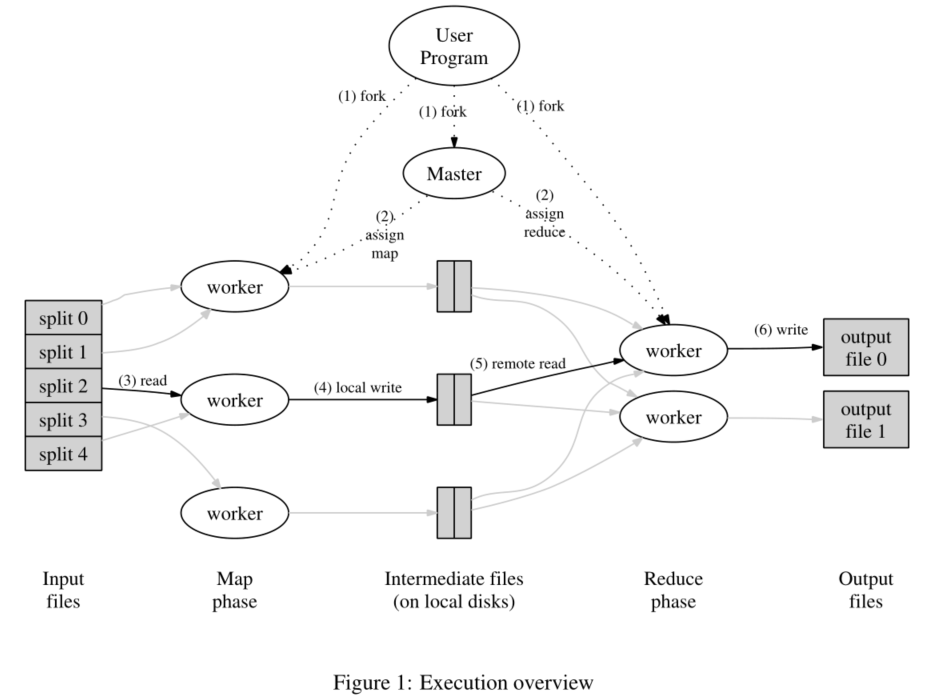
GFS是为了运行mapreduce而设计的