分布式 - MapReduce论文阅读
MapReduce
问题理解:
过去,处理大量数据的计算时,通常依赖于一台“超级电脑”,但机器计算能力仍然是有限的,这种方式无法解决无限大规模的数据。
MapReduce作为一种分布式并行计算的框架,它主要从分治的角度出发,能够高容错地组织许多一般性能的机器,将大规模问题进行拆解,在并行计算后再做整合,解决了大规模运算的问题。
现实生活中通常应用于一些分治问题:
- 词频统计
- 网页抓取
- 日志处理
- 查询请求汇总
Hadoop架构中,包含三大组件:分布式文件系统HDFS, 分布式计算组件MapReduce, 资源调度管理系统YARN
组成部分:
输入一组kv,生成一组kv。
MAP函数获取一个输入,并且生成一组中间的KV,
MapReduce库把与同一中间键i相关联的所有中间值组合在一起,通过迭代器传递给Reduce函数。
Reduce函数接受中间键i和键对应的一组值,把值合在一起,形成一个key更小的值集。一般每次只生成0或1个输出值。
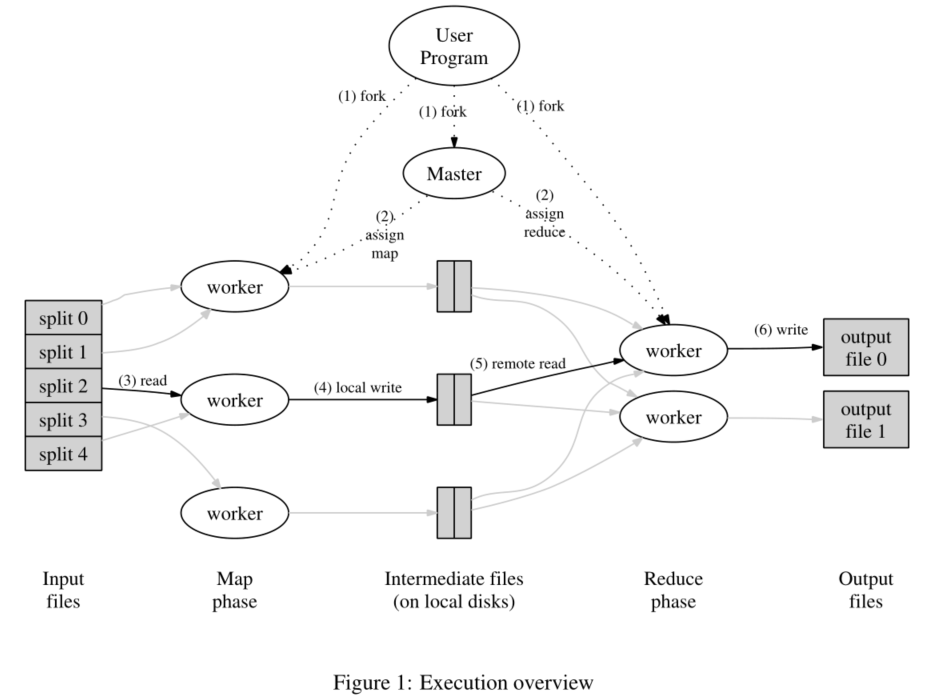
M-R工作基本步骤:
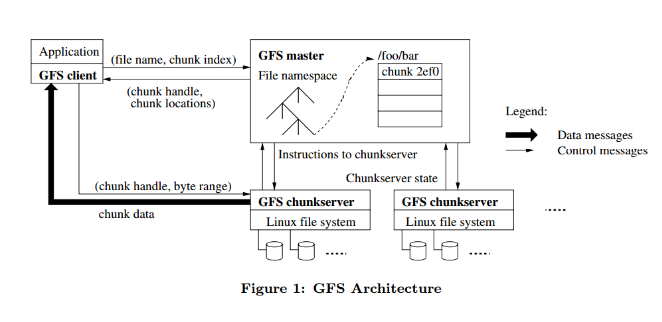
- 输入文件,MapReduce库分割成M个片段,每个片段16-64MB,然后在一群机器上启动程序的副本
- 其中一个副本是Master,其余是workers,总共有M个map任务和R个reduce任务需要分配。由主进程挑选空闲的workers分配一项任务。
- 分配到map任务的worker读取内容(被拆分好的一部分),从输出数据中解析出KV,传递给Map函数,然后把生成的中间KV存在内存
- 定期写入本地磁盘,并分区R个区,然后传地址给master。
- master通知reduce任务的workers这些位置,然后用RPC读取map的workers这些数据(直接从map workers传到reduce workers)。当reduceWorker读完所有中间数据后,按照键排序,以便将所有相同键的项组合。(排序是必须的,如果中间数据量大到内存不够了,用外部排序)
- reduceWorker遍历已排序的中间数据,按照键值和对应的一组中间值传递给Reduce函数。reduce函数的结果加到此分区的输出文件中
- 所有map和reduce任务完成后,master唤醒user程序。这时user程序中的MapReduce来return结果,一般所有分区输出文件同时输出传递给另一个MapReduce函数,不需要合并为一个文件。
数据结构:
每个map和reduce任务,保留存储状态(空闲,进行,完成)和工作计算机的标识(非空闲)
master是map任务中间文件位置的接受管道,master存储R个中间文件的位置和大小,map任务完成后,master接受信息更新,并且递增地传给正在进行的reduceWorkers
容错设计:
workers failure
master定期ping(心跳机制)每个worker如果有worker没有响应 或者 工作线程故障 ,就标记为失败,其上的任务重置为初始空闲状态,可以放在其他works上调度。
对于map任务故障,直接全部重新执行,因为输出存储在故障计算机上,无法访问。
对于reduce任务,只要接下来换机器执行,因为输出存储在全局文件系统中。
A执行map任务的时候坏了转给了B,那么对应执行reduce的workers需要重新执行,从B读取数据
master failure
写入master数据结构的检查点,master终止之后,可以从上一个检查点状态重新启动新的副本。
维护一个检查点,当宕机后从检查点恢复
避免语义冲突
无论是Map还是Reduce,worker输出都会先将结果暂时写在一个私有的临时文件中,等到任务完成后,再重命名该临时文件。目的是防止多个任务写在同一个文件中,导致内容语义冲突。依靠 文件系统提供的原子重命名操作 来确保最终文件的系统状态仅包含执行一次任务所产生的数据。(这一点6.824Lab并未体现,论文里有说明)
举例子:M的一次输出可能被R1读取并正在执行,M的另一次输出可能被R2读取了
本地化
如果任务失败,将在输入数据的副本附近调度map任务,大多数是本地读取的,不会消耗带宽。
任务粒度
任务数量M和R远大于计算机数量(当然有个上限),调整动态负载平衡。 R受到用户限制,一般是机器数量的小倍数
任务备份
问题:有些worker机器运行落后,最后几个任务要一直等着。
解决方案: 当一个MapReduce系统快完成的时候,主线程调度正在进行的任务进行备份执行(其余空闲的worker进行重复任务),只要主执行或者备份执行有完成的,那这个任务就被标记完成。这样加了少量计算负担,能提升时间较多
优化拓展
分区函数
用户指定M和R,使用分区函数对数据进行分区。要求平衡的分区,有时候希望相同的输出文件结束。。。
中间结果序列化
保证给定分区中,中间KV按照K升序处理,方便输出文件被查找,以减轻Reduce任务负担。
组合函数
中间键有时候有大量重复计算,原本都需要单独发给reduce任务计算,然后合并。
现在可以在map任务的计算器上指定一个合并函数,执行合并后写入一个中间文件,发给reduce任务。这样可以提高操作速度。
这种部分合并的combiner函数和reduce函数代码一致(除了输出的位置)。
输入输出类型
支持不同格式读取输入数据,读取器不一定需要提供从文件读取的数据
跳过坏记录
数据集并不能保证完全是正确的,如果有一行记录是错误的导致map任务崩溃,不断的重试最终使得整个程序不能结束。因此必然需要跳过这一段错误的记录,如何跳过呢?每个map任务要捕获异常,通过安装信号的方式,在程序退出之前执行安装的信号函数把执行到的文件的行号offset等信息发送给主节点。 主节点在下次调度的时候 将这些offset处的记录作为黑名单列表传递给新的map任务,执行时会对此处的记录跳过执行。
状态信息
状态页面可以查看所有任务的进度,心跳跳中附加状态信息,方便用户查看做任务的执行进度
计数器工具:对各种事件记录,在任务函数中调用incre,定期传给master以更新
lab1设计
主要思路:
map 处理,用ihash处理下key分成Nreduce份用json编码后写出到”mr-x-y”文件。
看MapReduce原文论文这步是有排序的,因为真正生产活动数据量是非常巨大的,map端提前排序好后,reduce的排序压力会减小很多,lab1这里数据量小,排不排序无所谓。
map 处理结果 返回kv,存储在中间文件中,中间文件命名 mr-X-Y X是map任务号,y是reduce任务号;
map阶段应该将中间键划分为nReduce的存储桶,这里只用了一倍reduce数量也就是**%NumReduce**;每个映射器都应创建NumReduce个中间文件,存在main目录下以供Reduce任务使用
reduce再都读取中间文件;Worker实现将第X个Reduce任务的输出放入文件MR-OUT-X中。Done()方法中,在MapReduceJob完全完成时返回TRUE;此时,mrcoherator.go将退出。当作业完全完成时,工作进程应该退出。
因为真正分布式worker都不在一个机器上,涉及网络传输,所以用lab1采用的是json编码解码走个过场