分布式 - MIT6.824/2023-lab3
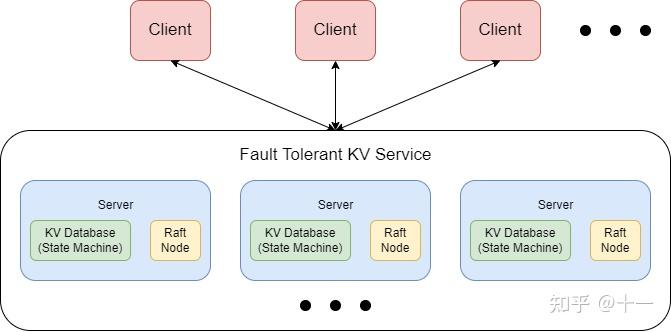
lab3是一个基于Raft的容错KV存储服务
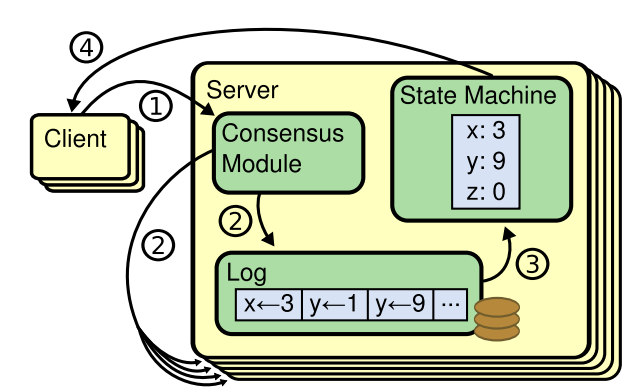
Clerk向k/v service发送三个RPC:Put Append Get,Clerk通过RPC与servers交互。这三种操作都要经过raft层共识添加到log后,再通过applyCh返回给上层的KV server, server再根据applyMsg作出相应动作就可以了。
Get/Put/Append 方法需要是线性的,对外表现是一致的,我理解就是说并发情况下 对外表现的线性一致性:
后一次请求必须看到前一次的执行后端状态;并发请求选择相同的执行顺序,避免不是最新状态回复客户端;在故障之后保留所有确认的客户端更新的方式恢复状态
3A-Key/value service without snapshots
基本思路
每个kv service有一个raft peer,Clerks把Get/Put/Append RPC发送给leader的kv service,进一步交给Raft,Raft日志保存这些操作,所有的kv service按顺序执行这些操作,应用到kv数据库,达到一致性
- Clerk找leader所在kv service和重试RPC的过程;
- 应用到状态机后leader通过响应RPC告知Clerk结果,如果操作失败(比如leader更换),报告错误,让他重试
- kv service之间不能通信,只有raft peer之间RPC交互
重复RPC检测 - 怎么保证线性一致性问题
如果收不到RPC回复(no reply),一种可能是server挂了,可能换一个重新请求;但是另一种是执行了但是 reply丢包了,这时候重新发的话会破坏线性一致性。
解决方案是重复RPC检测:
clerk每次发RPC都发一个ID,一个Request一个ID,重发相同;在server中维护一个表记录ID对应的结果,提前检测是否处理过;Raft的日志中也要存这个ID,以便新的leader的表是正确的
如果之前的请求还没执行,那会重新start一个,然后等第一个执行完后表就有了,applCh得到第二个的时候看表再决定不执行了。
请求表的设计
每个客户端一个条目,存着最后一次执行的RPC,index是clientID,值是保留值和编号;
RPC处理程序首先检查表格,只有在序号 > 表格条目时才Start()加入条目;当操作出现在applyCH上时,更新请求表中该client的序号和值,唤醒正在等待的RPC处理程序,返回结果值。
这样的效果是:每个client同时只有一个未完成的RPC,每个client对PRC进行编号;也就是说当客户端发送第10的条目,那之前的都可以不要,因为之前的RPC都不会重发了。
client
每个client有一个clientID,是一个64位的随机值;
client发送PRC中有 clientID 和 rpcID,重发的RPC序号相同;
3A - BUG
- 我之前以为是ok!自动判断RPC超时回复这样理解是错误的!
RPC超时不是天然就会自动返回的,应该要自己设置设置RPC超时时间并返回false,
例如 raft并没有成功apply这个操作的log entry, 而恰好此时又没有别的client有操作请求,那么raft就不会推进共识,handler会一直等待raft,而RPC也是不会返回false的。这时候整个系统就一点动作都没了。所以我们需要在两端的任意一端实现超时监测,一旦发现超时,就重新发送相同的操作请求。我才用的是在RPC处理函数中添加定时器管道,如果定时器超时说明RPC处理超时,需要重新发送RPC。
具体的实现山也做了部分修改:
本来使用的是条件变量等着表的更新,但是用select chanl可以用非阻塞处理处理不同的通道,而且可以直接传递变量,不需要重新查表了。
用 map[int]chan int处理 对应不同的index,提交时到对应chan中,index的唯一性,考虑添加chan和删除,delete(kv.chanMap, 1) 删除键为1的元素,自动销毁chan,考虑请求满足之后就会删除,同时存在chan也不多,先采用这种方案。
1 | func (kv *KVServer) PutAppend(args *PutAppendArgs, reply *PutAppendReply) { |
- 设计是定时器在server中,那server如果挂了,也是没有reply,不返回了,这种情况怎么解决?
这是服务器的问题,不是raft一致性没有达到,应该是RPC会返回false。
- 负责应用请求的applCh拿到后发现表中已经有rpc,没有执行也没有返回,导致RPC得不到回复。
正确的做法是不执行,但是要返回值。查看rpc通道还存不存在,如果存在,说明上一次没有回复rpc(可能是上次chanl还没创建好);如果不存在,说明这个条目是重复的条目,不需要返回RPC了
- leader的applyCh读取不到数据了,导致一直超时,一直操作不了数据库。
原来是lab2 raft日志同步有问题,也就是在start后立即发起心跳引起的。修改后导致添加了额外的心跳,那在发送心跳的过程中snapshot了,会导致preLogIndex比follower的lastIncludeIndex还要小。修改后,raft提前考虑这种情况,然后返回xindex为realLastlogIndex。
3B-Key/value service with snapshots
基本思路
添加了一个MaxraftState指示持久RAFT状态允许的最大大小(以字节为单位)(包括日志,但不包括快照)。**将MaxraftState与Persister.RaftStateSize()**进行比较。当Key/value service检测到RAFT状态大小接近此阈值时,需要应该通过调用RAFT的Snapshot来保存快照。
如果MaxraftState为-1,则不必创建快照。
MaxraftState应用于RAFT作为第一个参数传递给Persister.Save()的GOB编码的字节。
server重启的时候,从persister读取快照并且恢复
- 快照需要存储的信息和快照的时机考虑清楚,k/vserver的重复检验必须跨越检查点,所以任何状态必须包含在快照中。可能快照需要请求表因为一恢复就要启动重复检验的功能,应该是需要保存kv数据库,也就是状态机的状态
- 快照中数据必须大写
快照功能实现
快照时机:
考虑server和raft交互的时候,考虑server状态机和raft日志改变的时候。
在raft通过applyCh提交给server的时候,检查是否快照。快照的内容包含至这个index之前,所以在应用状态机之前检查快照。
快照操作:
- 检查stateSize,如果超出就做快照。
- server做快照,需要保存数据库和请求表snapshot,保存index(因为之后还要传给让raft,且applyCh可能接受快照的,那时候需要比较快照的latest性)。然后把snapshot和index传给raft做快照,也就是保存raftstate
- 恢复操作,server恢复状态机、请求表,raft恢复state
- appCh可能会传条目,也可能传快照,分开处理。如果传的是快照,之前raftstate已经更新,判断快照合理性,应用快照。
3B-bug
- raft提交一个snapshot并被server应用之后,又提交了一个相同index的Op,但内容是nil
原因的是server主动快照时在新applyCh传入条目的应用之前拍的,也就是传入快照函数的index是新条目的index-1而不是index
- 落后较多raft接受到RPC快照同步的时候,没有成功。仔细看原因是applCh写入snapshot的时候阻塞了。
- raft下标越界,可能原因是用chan的时候解锁,锁被抢走了,修改了lastIncludeIndex,当chan写完获取锁的时候,已经改变了raft的状态。
对2 3bug的修改,主要是把安装快照的RPC中传给上层的chan放到最后处理,这时候PRC导致的状态更新已经完成了,chan放锁给其他的用来修改raft状态也没关系。所以说chan不仅要记得解锁,还锁,而且要考虑在chan解锁期间发送的不确定性问题。
一些总结
基于raft的一个简单kv系统,主要是保证线性一致性,处理一些case的锁抢占、死锁和RPC交互问题。
好看点的写法是函数中间需要加锁的部分单独移出去做新函数,不然很丑而且容易忘记解锁。