分布式 - 基于Raft集群的分片kv数据库(MIT6.824/2023-lab4)
1. Structure
1.1 设计目标:
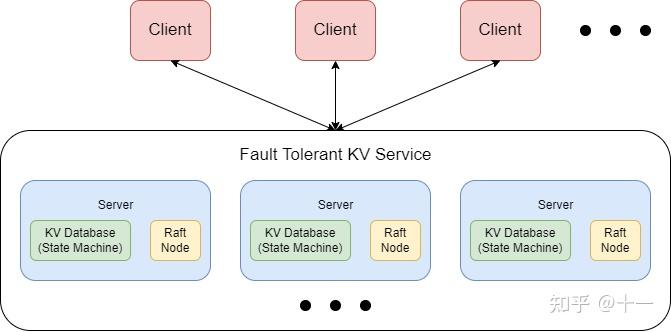
实现一个基于Raft集群的“分布式的,拥有分片功能的,能够加入退出成员的,能够根据配置同步迁移数据的,Key-Value数据库服务”
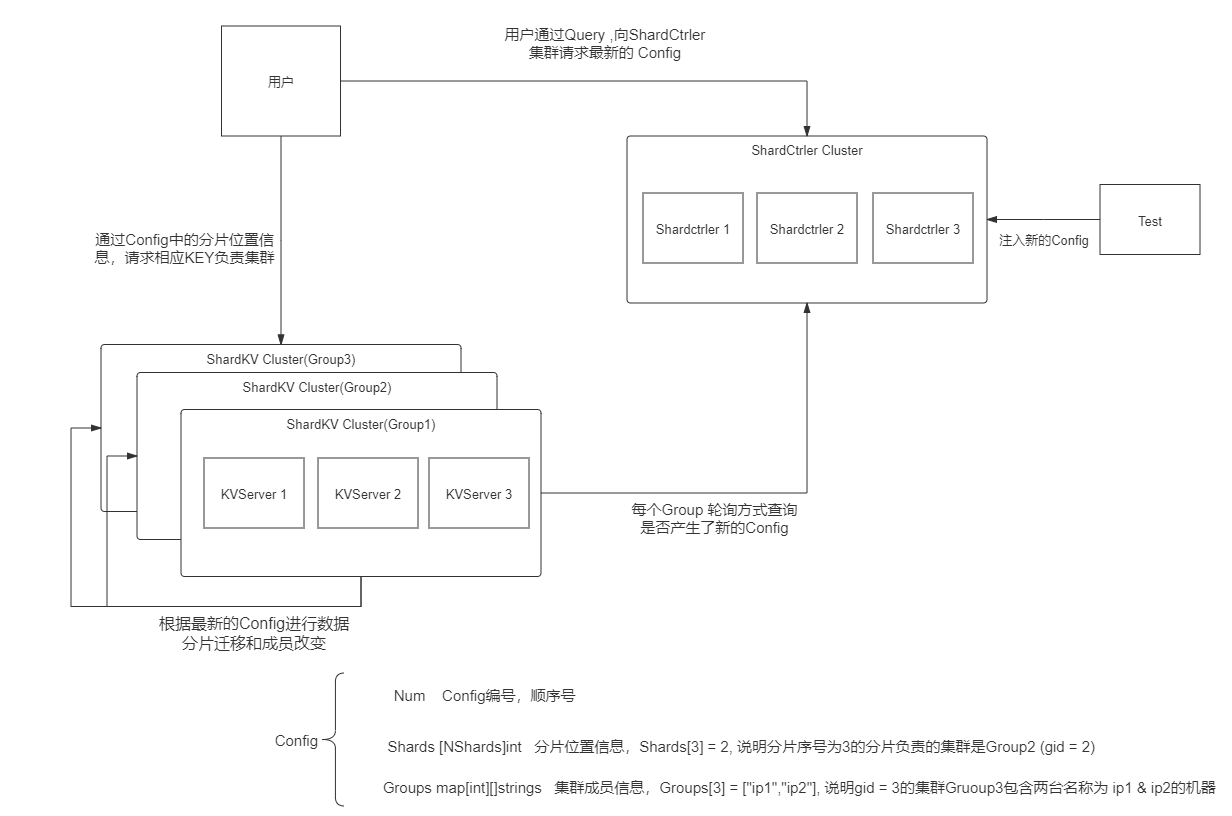
Client:向ShardCtrler请求获得最新的Config,Config中有”数据存在哪“的信息;然后向目标分片ShardKV server发送Put Appand Get请求。
ShardCtrler:管理Config数组,保存有历史版本的配置信息,并且能够根据ShardClient的请求构建新配置,接受请求包括:
- Query:查询某个版本或者最新版本;
- Leave:让某些Group离开集群
- Join:让某些Group加入集群;
- Move:强制让某个shard分片移动到指定Group中
ShardServer:由多个Group组成,每个Group保存数据库中的一部分数据分片,所有Group构成一整个数据库。每个组通过RPC向ShardCtrler轮询获取新配置,组与组之间通过RPC按照新配置交换数据分片管理权。
每个Group和ShardCtrler都是分布式的,有底层Raft节点保证容错和一致。
2. 设计思路:
2.1 ShardCtrler 分片配置管理器
1 | type ShardCtrler struct { |
ShardCtrler决定哪个副本组应该为某个分片服务;此信息称为配置。配置随时间变化,由ShardCtrler接受ShardClient的请求对配置进行更改。
第一个配置应该编号为零。它不应包含任何组,并且所有分片都应分配给 GID 零(无效的 GID)。然后ShardClient发送第一个分片配置给ShardCtrler,开始基于分片处理数据。
关于配置的请求包括Query、Leave、Join、Move。
- 除了Query是简单查询的天然幂等操作外,其他请求都需要考虑网络波动和超时重传机制,来设计幂等性,这里用请求表的方式进行重复检验;
- 这些请求都要通过下层Raft集群进行一致性通过后再做出相应,保证机器的容错性,防止在机器故障或者失联的情况下返回错误信息;
- 其中Leave、Join请求后,需要对所有Group进行reBalance处理,尽量保证负载均衡
2.1.1 servers reBalance方案
整体来说,想要用最少的移动次数调整成负载均衡的模式,就是多向少进行移动,但是又因为是整数个Shard的原因,那必然会有些Group的Shard会大于平均数,但是最多只会多1个。具体思路如下:
按照更新后的server组数计算平均数,以及余数,维护一个未分配的shards组成的数组
首先对原方案做调整,向新平均数靠近,首先回收超过平均数的Groups多出来的shards存到未分配的数组中:
如果有余数,可以容许余数个Group的shard值是平均数+1,超出余数个后只能容许是平均数;
如果没有余数,只能容许所有的Group的shard值是平均值;
把以上两走情况结合,直接按照left>0判断,容许范围是average还是average+1
- 最后对没有达到average的server增添,直到未维护的shard全部分配完成。
因为之前以及保证了left个average+1的server,那么其他的server都是average个。
这样可以达到预期两个效果:
1.除非必要(超出平均数或平均数+1),否则不移除原有的切片。
2.对于不够平均数的Group,添加新的切片,达到average,不同Group之间负载最多相差1个分片。
2.1.2 为什么要分片?
分片的原因是性能。每个副本组仅处理几个分片的放置和获取,并且这些组并行操作;因此,总系统吞吐量(每单位时间的输入和获取)与组数成比例增加。
2.1.3 分片配置为什么要修改?
分片存储系统必须能够在副本组之间转移分片。一个原因是一些组可能比其他组负载更多,因此需要移动分片来平衡负载。另一个原因是副本组可能会加入和离开系统:可能会添加新的副本组以增加容量,或者现有的副本组可能会因维修或退役而脱机。
2.2 Sharded Key/Value Server 分片数据库集群
1 | type ShardKV struct { |
2.2.1 multi-raft结构:
所有涉及修改集群分片状态的操作都应该通过 raft 日志的方式去提交,这样才可以保证同一 raft 组内的所有分片数据和状态一致。
apply结构如下:
1 | func (kv *ShardKV) applier() { |
2.2.2 方案
配置更新方案:
配置更改由Raft集群中的leader发起,具体实现如下:
- 开一个后台协程configChangeChecker,定时轮询shardctrler,通过RPC拉取下一个新的配置,检查是否可以应用下一次config;
- 开一个后台协程shardsPullChecker, 定时轮询, 如果下一个新配置可用,是否通过RPC拉取Pull新配置中当前库内没有的分片;
- 开一个后台协程shardDelChecker, 定时轮询,是否新配置的新分片已经拿到了并应用,如果完成拉取则通过RPC通知这些分片的原管理者ex-ower,可以删除分片进行垃圾回收;
采用的RPC方案:
PullShards() Group之间,用于拉取新配置的新分片;
DelShards() Group之间,用于通知分片原主可以删除了;
Get() Put() Append() client与kv-server之间,用于对数据库发送请求和接受回复;
Query() Leave() Join() Move() (Sharded K/V Server 或 client) 与 ShardCtrler 交互配置情况
客户端请求方案:
需要判断分片是不是在当前的gid中,如果不是先拒绝
如果处在分片迁移过程中,迁移发出方需要立刻停止对该分片请求的控制(一迁移就修改为拒绝),接受方在迁移完成整个分片前停止对该分片的控制(全部迁移完再修改)
重复检测的客户端请求也需要按照分片处理,因为数据迁移的时候,rpc的请求列表也是迁移的一部分,不然重复检测在迁移后起不到作用,相同的client的请求要重新开始记录。比如上一次是发给旧的group的请求,执行了但网络原因没有回复client,client重复请求的时候,当前向新的client发送请求,需要旧的server的请求表才能进行重复检测
请求表分片的效果是:分片的数据和它的请求表是一体的。
2.2.3 通过分片状态判断配置更改的进度
每个分片状态包括以下四种类型:
1 | StateOk = "OK" // 完成 |
- 可以获取新配置的条件: 当前配置的所有分片状态都是OK的,且拉取的新配置只能是当前配置+1;
- 新配置一致性通过并开始应用:修改需要拉取的新分片的状态为In,需要被移走的分片状态为Out;
- 拉取完成:修改为Wait状态等待Pull RPC发起方说明已经拿到了(可能因为网络原因或机器故障Pull发起方没有接受到,所以需要不能保证都被拉取);
- 删除分片: 指定分片状态是Wait,表示已经被Pull了且应用后,分片的new-ower回发起删除RPC告知ex-ower可以进行垃圾回收;
2.2.4 为什么不能设计配置修改和同步新shard代码顺序执行,而要用异步并行处理? - 一个欠考虑的坑
同步新shard肯定是在配置修改同步完成后把分片状态改成Out或者In执行后之后做的。但是简单的设计新配置应用后区拉取新分片的代码时错的!
考虑这种case,在更新配置完成后再去开goroutine拉取新配置,如果更新配置完成后还没拉取完成就宕机,那恢复之后也用于不回去拉取这个shard。这种错误的原因是raft层的持久化保证了apply之后的条目是不会再修改或应用的(否则有可能一些旧值把新的修改了),也就是已经通过了,持久化后不需要再提交一次。导致不会进入pull shard的函数了!!
所以程序应该设计为选择开一个新的groutine定期检查是否要拉取,这样重启后也能继续处理pullshard操作,而且不会导致死锁。
同样的到底要选择开一个新的groutine定期检查是否要删除分片。
2.2.5 为什么需要设置DelShards RPC而不是被拉取自行删除?
因为在pullshard完成后还不能确定RPC发送方真正拿到了shard并且一致化通过并应用了,保持不能进入下一个config,等待真正用上了新的分片,发送DelShards RPC删干净后进入下一个config check。
2.2.6 PullShards PRC 和 DelShards RPC的重复检测
PullShards PRC:
args.NewConfigNum > kv.curConfig.NumRPC 接收方还没有更新到这个配置,让请求方再等等重新请求
args.NewConfigNum < kv.curConfig.Num 过时的RPC 舍弃这个RPC。因为被pull放只有 被通知可以删除整个shard后才会更新配置,所以被pull方配置更新则需求方已经拿到shard,说明只能是过时的RPC.
DelShards RPC:
因为DelShards RPC是类似于客户端请求,直接放到raft中,等apply后用chan回复。再次收到这个kv.curConfig更新不能保证接收方已经不在wait了。所以重复的RPC也需要返回OK(类似于客户端请求)。
考虑RPC失败的不确定性,就算回复是过时的RPC,也就是接收方已经删除了,发送方处理回复也需要添加一个Op到raft层。而是把Op的有效性判断,交给apply。
什么会出现args.ConfigNum > kv.curConfig.Num?
当G1宕机恢复的时候,正在走他曾经的条目,这时候curConfig比较小,其他在wait的server会发送最新的args.ConfigNum。这时候应该让其他server等一会,等G1归来之后,拉平ConfigNum,才能有效的接受RPC。
2.2.7 为什么配置只能+1步进更新
原理和raft层的log处理一样,因为配置修改不是整个替换而是局部分片转移,跳过一些配置,会失去一些中间状态的数据。
例如,当前GroupA在config1,GroupB在config6,然后某个shard的数据在config6的状态下是属于A的,在config1的状态下是不属于A的,这时候客户端在config6下向Server提出Put/Append请求,然后会一直失败,因为这个时候的server,GroupA认为数据不是它的,B也认为不是它的。这时候到达了config7,在config7下,该shard是属于B的,若A直接到达了config7,则本应该在6到7过渡的过程,数据从A迁移到B,但是A跳过了6,则B就丢失了这一部分数据。
2.2.8 当数据迁移时,不能拉取新配置
这个很好理解,例如当前GroupA在config1,GroupB在config1,然后二者想要更新到config2,这个过程是A向B传数据。假如A发送了数据就认定自己发送完了,就拉取新配置到了2,但是B没接收到数据,之后A在config2时就不会发原来的那些数据给B了,因为它认为自己没有了这些数据。B就会一直没有接收到这些数据。
2.2.9 当然数据迁移的过程中分片是不能处理的
如果一个副本组丢失了一个分片,它必须立即停止向该分片中的key提供请求,并开始将该分片的数据迁移到接管所有权的副本组。如果一个副本组获得一个分片,它需要等待让前任发送全部的数据给它,然后才能接受该分片相关的请求
这个也可以理解,因为分片在迁移过程中没有Group对其有管理权。
优化的方式是按照片进行迁移,而不是一个配置迁移多片,这样只要单个分片迁移完成就可以进行该片的处理。
3. 一些优化
3.1 节点重启时添加空日志加速状态机更新
- 重启恢复到快照的时候,之后继续同步卡住,这最后处理的关键RPC对应的日志并没有重新被commit。研究后发现原来,此时 leader 的 currentTerm 高于这个RPC对应的日志的 term,也就是说没有当前leader的term的新日志加入导致raft层停工了,所以很多日志没有apply上来。则优化添加一个新的空日志来推动日志apply进程:
- leader 在当选时要先提交一条空日志,这样可以保证集群的可用性。这条空日志不能在raft层添加,
- 在server层开一个协程负责定时检测 raft 层的 leader 是否拥有当前 term 的日志,如果没有则提交一条空日志,这使得新 leader 的状态机能够迅速达到最新状态,从而避免多 raft 组间的活锁状态。
- 不能在raft层添加空日志,因为lab2可能过不了。raft层应该遵循严格的规则。
3.2 状态垃圾收集
当副本组失去分片的所有权时,该副本组应从其数据库中删除丢失的键。保留它不再拥有且不再满足请求的价值是一种浪费。但是,这给迁移带来了一些问题。假设我们有两个组,G1 和 G2,并且有一个新的配置 C 将分片 S 从 G1 移动到 G2。如果 G1 在转换到 C 时从其数据库中删除 S 中的所有键,那么当 G2 尝试移动到 C 时,它如何获取 S 的数据?
- 对策:前面提到实现用go kv.shardDelChecker()定时检测已经拿到的shards,保证数据被拉到后,用DelShards RPC通知ex-ower可以删除整个shards相关的所有数据,然后把状态改为OK。
3.3 配置更改期间的客户端请求
处理配置更改的最简单方法是在转换完成之前禁止所有客户端操作。虽然概念上很简单,但这种方法在生产级系统中并不可行;每当机器被带入或取出时,它会导致所有客户端长时间停顿。最好继续为不受正在进行的配置更改影响的分片提供服务。
- 对策:数据迁移按照每个shard进行区分,数据库的数据和状态也按照shard进行区分。假设某个副本组 G3 在转换到 C 时需要来自 G1 的分片 S1 和来自 G2 的分片 S2。我们真的希望 G3 在收到必要的状态后立即开始服务分片,即使它仍在等待其他分片。例如,如果 G1 关闭,一旦 G3 从 G2 接收到适当的数据,它仍应开始为 S2 提供服务请求,尽管到 C 的转换尚未完成。